CMPUT 404
Web Applications and Architecture
Part 04: HTTP
Created by
Abram Hindle
(abram.hindle@ualberta.ca)
and Hazel Campbell (hazel.campbell@ualberta.ca).
Copyright 2014-2023.
Context: FTP vs HTTP
- 1971
- Just files and lists of files (aka directories)
- Out of band communication (files xferred via 2nd connection)
- Firewalls prevent server connecting back to client (fixed with passive mode)
- 200 OK
- Must log in everytime, but by convention anonymous logins
- 1991
- Sends content, not files
- Responds to requests: GET/POST/DELETE/PUT/HEAD/etc.
- Allows extra information (headers) and arguments (queries) with commands
- 200 OK
- Default: anonymous, no log-in
- Dynamic content (generated at the time the request is received)
Context: Gopher vs HTTP
- 1991
- Sends files, directories
- Simple
- Hypertext
- Limited file types: menus, text, binary, gif, image
- Death by licensing and adoption
- 1991
- Sends content, not files
- Responds to requests: GET/POST/DELETE/PUT/HEAD/etc.
- More complex
- Any type of content
HTTP
- Hypertext — "over" text
- Transport — Move it/communicate it
- Protocol — an agreed-upon method of communication
- Accepted custom headers — allowing for extension, new features
- Allowed for a more request/command oriented pattern (remember the command pattern)
- Relied on the pairing of web clients and web servers
- Relies on URIs to describe resources, allows more than 1 resource to be hosted on 1 server
- RFC: The standard for HTTP: http://tools.ietf.org/html/rfc2616
- RFC: Request For Comments
- Hypertext Transfer Protocol — HTTP/1.1
- IETF's definition of HTTP/1.1
- No matter what I say about HTTP, the RFC is the final word.
HTTP Basics
- HTTP uses TCP (usually)
- HTTP uses TCP Port 80 (usually)
- HTTPS allows for ENCRYPTED HTTP
- HTTPS uses port TCP 443 (usually)
- HTTP can work over IPV4 and IPV6
- HTTP requests are made to addresses called URIs
HTTP Commands
Every HTTP command is made to a URI.
- GET – Retrieve information from that URI
- POST – Run search, log-in, append data, change data
- HEAD – GET without a message body (for caching)
- PUT – Store the entity at the that URI
- DELETE – Delete the resource at that URI
- PATCH – Modify the entity at that URI
- OPTIONS – What options a resource can accommodate
- TRACE – Debugging / Echo Request
- CONNECT – Tunneling proxy over HTTP
URI or URL?
URI- Universal Resource Identifier
- Identifies (points to) a resource
- Most URIs are URLs
- URL: Uniform Resource Locator
- Tells you how to get to a resource
- http://ualberta.ca/
- Some URIs are URNs
- URN: Uniform Resource Name
- Tells you the unique name or number given to a resource by some body (e.g. IETF)
- urn:ietf:rfc:3986
URLs
- Two main parts: scheme and everything else
- Common URL Schemes: http, https, mailto, file, data
- URL Schemes for older technologies: ftp, gopher, irc
- URI Schemes for new technologies: spotify:track:35zrlBOjpfDPMcZzglWOuV
URLs
- scheme
- :
- authority
- username:password@ (optional)
- hostname
- :port (optional)
- path
- ?query (optional)
- #argument (optional)
Username/password not used much anymore...
http://joe:hunter23@[::1]:8000/search.html?q=cat%20pictures&results=20#result-10
- scheme http
- :
- authority
joe:hunter23@[::1]:8000
- Username joe
- Password hunter23
- @
- Host [::1]
- :
- Port 8000
- path search.html
- ?query ?q=cat%20pictures&results=20
- #fragment #result-10
[::1] is IPv6 loopback address, like IPv4's 127.0.0.1
Absolute and relative URLs
-
http://[::1]:8000/images/web-server.svg
- Absolute authority, absolute path
-
/images/web-server.svg
- Implied authority, absolute path
-
images/web-server.svg
- Implied authority, relative path
![http://[::1]:8000/images/web-server.svg](http://[::1]:8000/images/web-server.svg){kind=link}
{kind=link}
{kind=link}
Absolute and relative URLs
| Where I am | The link | Where I go |
http://[::1]/f/d/1/a.html | http://google.com/ | http://google.com/ |
http://[::1]/f/d/1/a.html | //localhost/g/b.html | http://localhost/g/b.html |
http://[::1]/f/d/1/a.html | /g/b.html | http://[::1]/g/b.html |
http://[::1]/f/d/1/a.html | g/b.html | http://[::1]/f/d/1/g/b.html |
.. means go to parent folder
| Where I am | The link | Where I go |
http://[::1]/f/d/1/a.html | http://google.com/c/../E.html | http://google.com/E.html |
http://[::1]/f/d/1/a.html | //localhost/g/../b.html | http://localhost/b.html |
http://[::1]/f/d/1/a.html | /g/../b.html | http://[::1]/b.html |
http://[::1]/f/d/1/a.html | ../g/b.html | http://[::1]/f/d/g/b.html |
http://[::1]/f/d/1/a.html | ../../g/b.html | http://[::1]/f/g/b.html |
http://[::1]/f/d/1/a.html | ../../../g/b.html | http://[::1]/g/b.html |
. means go to the same folder we're already in
| Where I am | The link | Where I go |
http://[::1]/f/d/1/a.html | http://google.com/c/./E.html | http://google.com/c/E.html |
http://[::1]/f/d/1/a.html | //localhost/g/./b.html | http://localhost/g/b.html |
http://[::1]/f/d/1/a.html | /g/./b.html | http://[::1]/g/b.html |
http://[::1]/f/d/1/a.html | ./g/b.html | http://[::1]/f/d/1/g/b.html |
http://[::1]/f/d/1/a.html | ././g/b.html | http://[::1]/f/d/1/g/b.html |
http://[::1]/f/d/1/a.html | ./././g/b.html | http://[::1]/f/d/1/g/b.html |
Example URLs
-
http://uofa-cmput404.github.io/cmput404-slides/index.html
- Result: opens webpage (slides)
-
mailto:hazel.campbell@ualberta.ca
- Result: opens email client (new email to Hazel)
-
spotify:track:6i7BrJ729QLUemr0i4rLU2
- Result: opens Buddy Rich's version of Weather Report's Jazz hit Birdland in Spotify
-
tel:+1-211-867-5309
- Result: calls Jenny
Queries
URLs can have a query portion. Consider https://www.google.com/search?q=cat+pictures&ie=utf8
- Query portions can have one or more arguments
- Usually: key=value&key2=value2
- But some other formats exist, such as using other separators ; instead of &, or just having a string and no keys/values.
Fragments
URLs can have a fragment portion. Consider https://en.wikipedia.org/wiki/Methanol#Applications
- Jumps to some spot in the content
- Jumps to a time in a video: https://www.youtube.com/watch?v=dQw4w9WgXcQ#t=98s
- Jumps to a part of a page: https://en.wikipedia.org/wiki/Methanol#Applications
- Jumps to a slide: #/0
Why are URLs important?
- True names...
- Rumpelstiltskin
- The Laws of Magic!
- The Law of Names — Knowing the complete true name of an entity gives one control over it. http://deoxy.org/lawsofmagic.htm
- URL
- Knowing the complete true URL lets one request/command it.
- Like that URL for the weather... http://dd.weather.gc.ca/citypage_weather/xml/AB/s0000045_e.xml
- Knowing the complete true URL lets one request/command it.
URIs and Encoding
- Universal URIs have to be able to handle anything
- Even paths with spaces and other characters... (accents, punctuation, symbols, emoji...)
- For HTTP assume our URLs are Unicode UTF-8 encoded
- For characters that
aren't
in
-._~0-9a-zA-Z
we use % encoding
- RFC 3986
- %20 is space
- %e2%98%83 is ☃ (☃ in HTML)
-
<img src="../images/%E2%98%83.svg">gives us
- For domain names we use "punycode" encoding
- http://☃.net/ which is converted to http://xn--n3h.net/
URIs and Encoding Example
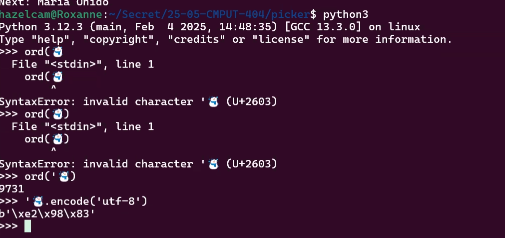
HTTP Example
Let's GET http://slashdot.org
- Request http://slashdot.org
- We see http, so we know it's going to be the HTTP protocol.
- No port specified so assume port 80.
- No path specified so assume /
- Open up a connection to port 80 slashdot.org
- Send...
GET / HTTP/1.1\r\n
Host: slashdot.org\r\n
User-Agent: mozilla/5.0 (x11; linux x86_64; rv:64.0) gecko/20100101 firefox/64.0\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\n
Accept-language: en-us,en;q=0.5\r\n
Accept-encoding: gzip, deflate\r\n
Connection: keep-alive\r\n
Upgrade-Insecure-Requests: 1\r\n
DNT: 1\r\n
\r\n- / in GET / is the path: we're asking for the root aka the index of the root directory.
- Host: slashdot.org... wait... I thought we already knew the IP address?
- Receive headers...
HTTP/1.1 301 Moved Permanently\r\n
Server: nginx/1.13.12\r\n
Date: mon, 14 jan 2019 23:18:22 gmt\r\n
Content-Type: text/html\r\n
Content-Length: 186\r\n
Connection: keep-alive\r\n
Location: https://slashdot.org/\r\n
\r\n- 301 Moved Permanently — your princess is in another castle.
- Receive content...
<html>
<head><title>301 moved permanently</title></head>
<body bgcolor="white">
<center><h1>301 moved permanently</h1></center>
<hr><center>nginx/1.13.12</center>
</body>
</html>- Webpage should redirect, following the location header, but in case it doesn't we're provided a short HTML page as well to explain the situation.
- So the browser doesn't show you this page, instead it goes to the location specific in the Location header.
location: https://slashdot.org/\r\n- It's sending us to the same slashdot page we asked for, except now, HTTPS!
- HTTPS: Encrypted... but... everyone still knows we're on slashdot. They might not be able to tell where on slashdot we are though.
- Time for our web browser to try again...
- Browser connects to slashdot.org on port 443.
- Browser initiates a TLS connection!
- For HTTP our layers look like:
- Ethernet
- IPv4
- TCP
- HTTP
- Browser connects to slashdot.org on port 443.
- Browser initiates a TLS connection!
- For HTTPS our layers look like:
- Ethernet
- IPv4
- TCP
- TLS
- HTTP
- Squeeze in TLS between TCP and HTTP.
- Open up a connection to port 443 slashdot.org
- Do a TLS handshake and open up TLS connection
- Send...
GET / HTTP/1.1\r\n
Host: slashdot.org\r\n
User-Agent: mozilla/5.0 (x11; linux x86_64; rv:64.0) gecko/20100101 firefox/64.0\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\n
Accept-Language: en-us,en;q=0.5\r\n
Accept-Encoding: gzip, deflate\r\n
Connection: keep-alive\r\n
Upgrade-Insecure-Requests: 1\r\n
DNT: 1\r\n
\r\n- Receive headers...
HTTP/1.1 200 OK\r\n
Server: nginx/1.13.12\r\n
Date: mon, 14 jan 2019 23:18:22 gmt\r\n
Content-Type: text/html; charset=utf-8\r\n
Transfer-Encoding: chunked\r\n
Connection: keep-alive\r\n
slash_log_data: shtml\r\n
Cache-Control: no-cache\r\n
Pragma: no-cache\r\n
X-xrds-location: https://slashdot.org/slashdot.xrds\r\n
Strict-Transport-Security: max-age=31536000\r\n
Content-Encoding: gzip\r\n
\r\n- 200 OK — okay, I did what you asked, everything went fine.
- Receive content...
- Just get garbled binary junk... no HTML
- Content-Encoding: gzip
- Web browser has to uncompress it first
- Decompress content...
<!-- html-header type=current begin -->
<!doctype html>
<html lang="en">
<head>
<!-- render ie9 -->
<meta http-equiv="x-ua-compatible" content="ie=edge,chrome=1">
... another 10 thousand lines of html ...
HTTP GET
Remember, we used HTTP GET on slashdot.org
- HTTP GET is a simple request to be sent that resource.
- It might be dynamic (resource is generated when the request is received by software on the server)
- It might be static (just a file sitting on the server, unchanging)
- It might be a mix of static and dynamic content
- We can send query parameters along an HTTP get in the URL
- It is considered bad if GET request causes the server to change data—we should use a different HTTP method for that
HTTP POST
- HTTP POST is a request to update, create, or generally interact with a URL.
- Can do things like ?queries but not limited by length.
- Used to submit HTML forms
- POST is expected to add or mutate data
- We can send query parameters along an HTTP get in the URL
HTTP POST
- URL-encoded parameters (percent-encoded)
- POST parameters are usually sent in a POST request body as application/x-www-form-urlencoded
- They could also be sent following RFC 2388's format:
multipart/form-data.
- http://tools.ietf.org/html/rfc2388
- Used when uploading files
HTTP POST Example
HTTP POST Example
Web browser sends:POST /04-http.html HTTP/1.1
Host: localhost:8000
User-agent: mozilla/5.0 (x11; linux x86_64; rv:64.0) gecko/20100101 firefox/64.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: http://localhost:8000/04-http.html
Content-Type: application/x-www-form-urlencoded
Content-Length: 0
Connection: keep-alive
Upgrade-Insecure-Requests: 1
DNT: 1
name=hazel&occupation=slide+makerHTTP POST and Forms
- Each form element has a name
- The name matches the key.
- E.g. <input name="occupation"> becomes occupation=
- The content of the input element becomes the value
multipart/form-data
- http://tools.ietf.org/html/rfc2388
- Use mime to send form data
- Multipurpose Internet Mail Extensions
- Mostly used to upload files as binary, but it can be used for any form
- Sends the content-size first and then asks the server if that's okay
- Server responds HTTP/1.1 100 Continue if it can handle that size of data
- Then the client sends the body
- Because of this interaction you can argue that this is a slower method (adds a round trip latency) since it requires the server to respond to the initial header before it sends the body.
- This is so the client doesn't try to send files that are too big for the server to handle, or of a type it can't handle, etc.
multipart/form-data Example
hindle1@st-francis:~$ curl -f 'what=1' -f 'suzie=q' -x post http://webdocs.cs.ualberta.ca/~hindle1/1.py --trace-ascii /dev/stdout
post /~hindle1/1.py http/1.1
user-agent: curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 ope
nssl/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3
host: webdocs.cs.ualberta.ca
accept: */*
content-length: 235
expect: 100-continue
content-type: multipart/form-data; boundary=----------------------------9edfbc1fb1b0- The boundary lets the server tell when one part of the form ends and another begins.
- The random number should be chosen so that it won't show up in the contents.
multipart/form-data
The server sends back:http/1.1 100 continue------------------------------9edfbc1fb1b0
content-disposition: form-data; name="what"
1
------------------------------9edfbc1fb1b0
content-disposition: form-data; name="suzie"
q
------------------------------9edfbc1fb1b0--<= recv
http/1.1 200 ok
date: mon, 13 jan 2014 23:37:30 gmt
server: apache/2.2.3 (red hat)
connection: close
transfer-encoding: chunked
content-type: text/html; charset=utf-8
<h3>form contents:</h3>
<dl>
<dt>suzie: <i><type 'instance'></i>
<dd>fieldstorage('suzie', none, 'q')
<dt>what: <i><type 'instance'></i>
<dd>fieldstorage('what', none, '1')HTTP 2
- 2015—24 years after HTTP
- Based on proposed SPDY protocol by Google: designed to reduce latency
- Only supported over TLS (HTTPS)
- Same methods, status codes, headers and URIs for compatibility
- Binary protocol: not viewable/debuggable/writable in plain text
- Compress headers for less bandwidth
- Headers are shown in lowercase:
locationinstead ofLocation
HTTP 2
- Pipelining:
- request request request ... response response response
- Push: psychic servers look into the future and sends clients content before they even request it 🔮
- Multiplexing:
- respreressponsonponsesee
Multiplexing and Pipelining
 Ilya Grigorik, Surma,
https://developers.google.com/web/fundamentals/performance/http2/#request_and_response_multiplexing, Retrieved 2019-01-17 under a Creative Commons Attribution 3.0 License
Ilya Grigorik, Surma,
https://developers.google.com/web/fundamentals/performance/http2/#request_and_response_multiplexing, Retrieved 2019-01-17 under a Creative Commons Attribution 3.0 License
HTTP 3
- 2022 - 7 years after HTTP 2
- HTTP 2 was still too slow! (For Google)
- Get webpages loaded faster
- Especially small ones
- TCP stopped all multiplexed streams if a packet went missing
- TCP handshake needed to complete before TLS handshake
- Runs over QUIC inside of UDP packets
Quick UDP Internet Connections
- QUIC provides the same guarantees that TCP provides
- Nickname: "TCP 2"
- TCP was specified in 1974!
- However, QUIC has lower latency
- Especially in the case of dropped packets
- Provides multiple "streams", TCP only provides one
- Integrates with TLS 1.3
- Avoid using multiple TCP connections to a single server
- Reduce high-latency TCP handshakes
- Reduce high-CPU TLS handshakes
- Requests and responses in both directions happening all at the same time, data is interleaved
- Requests/responses can be prioritized
Resources: RFCs
Resources
- Domain Names
- http://tools.ietf.org/html/rfc1035
- http://tools.ietf.org/html/rfc1123
- http://tools.ietf.org/html/rfc2181
- Paul Vixie on DNS: http://queue.acm.org/detail.cfm?id=1242499
- International domain names: http://www.unicode.org/faq/idn.html
License
Copyright 2014-2023 ⓒ Abram Hindle
Copyright 2019-2023 ⓒ Hazel Victoria Campbell and contributors

The textual components and original images of this slide deck are placed under the Creative Commons is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Other images used under fair use and copyright their copyright holders.
License
Copyright (C) 2019-2023 Hazel Victoria Campbell
Copyright (C) 2014-2023 Abram Hindle and contributors
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN.
01234567890123456789012345678901234567890123456789012345678901234567890123456789